DDIA Chapter 4 - Presentation
2024-02-16
This chapter introduces the concepts of encoding, how data structures are represented as bytes on a disk or over the network, and evolution, how we can change the structure of data (i.e. the schema) while maintaining backward and forward compatibility.
Backward and Forward Compatibility
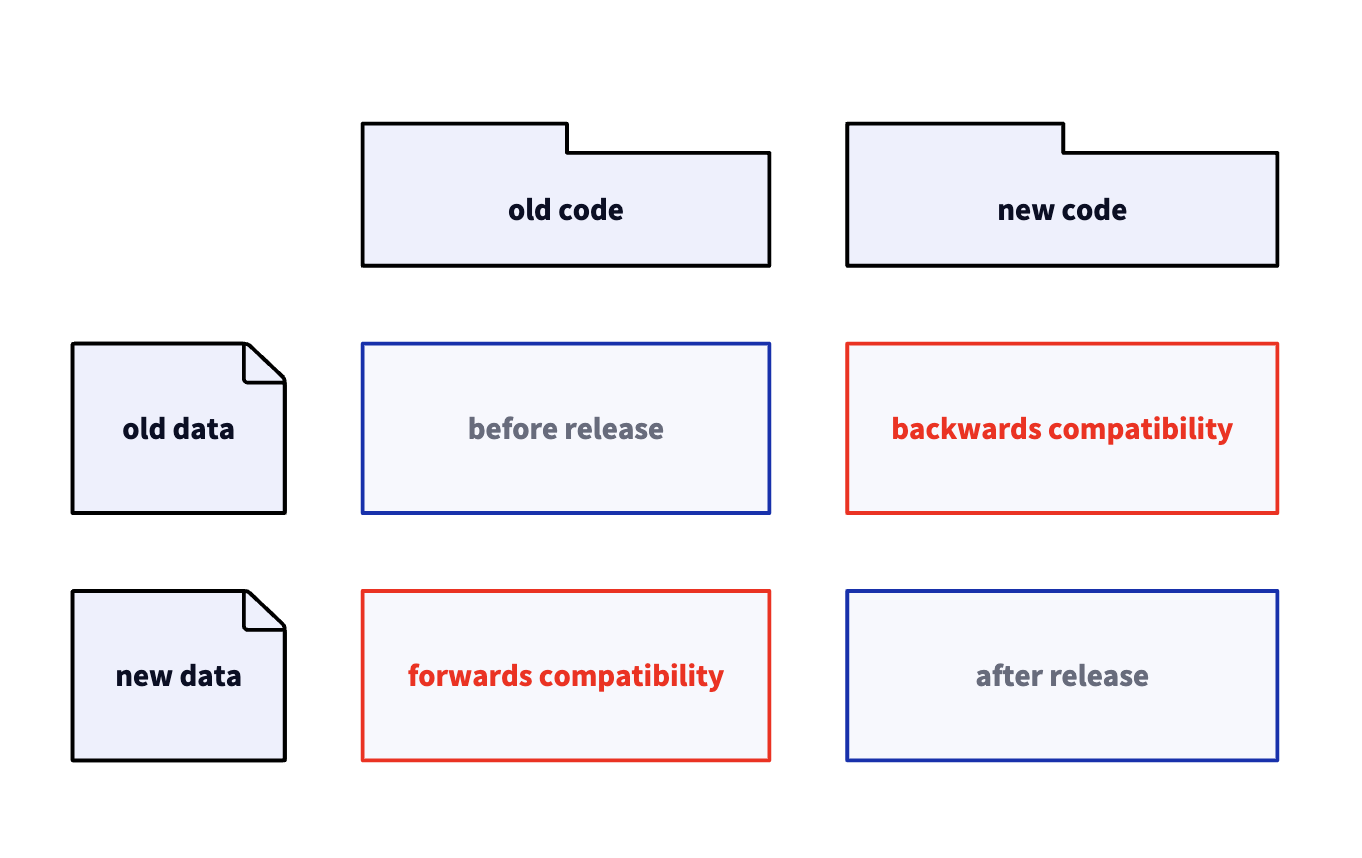
- Backward Compatibility: Newer code can read the data written by older code.
- Forward Compatibility: Older code can read the data written by newer code.
Different ways of encoding data may allow for either backward or forward compatibility or both (or neither).
MessagePack example
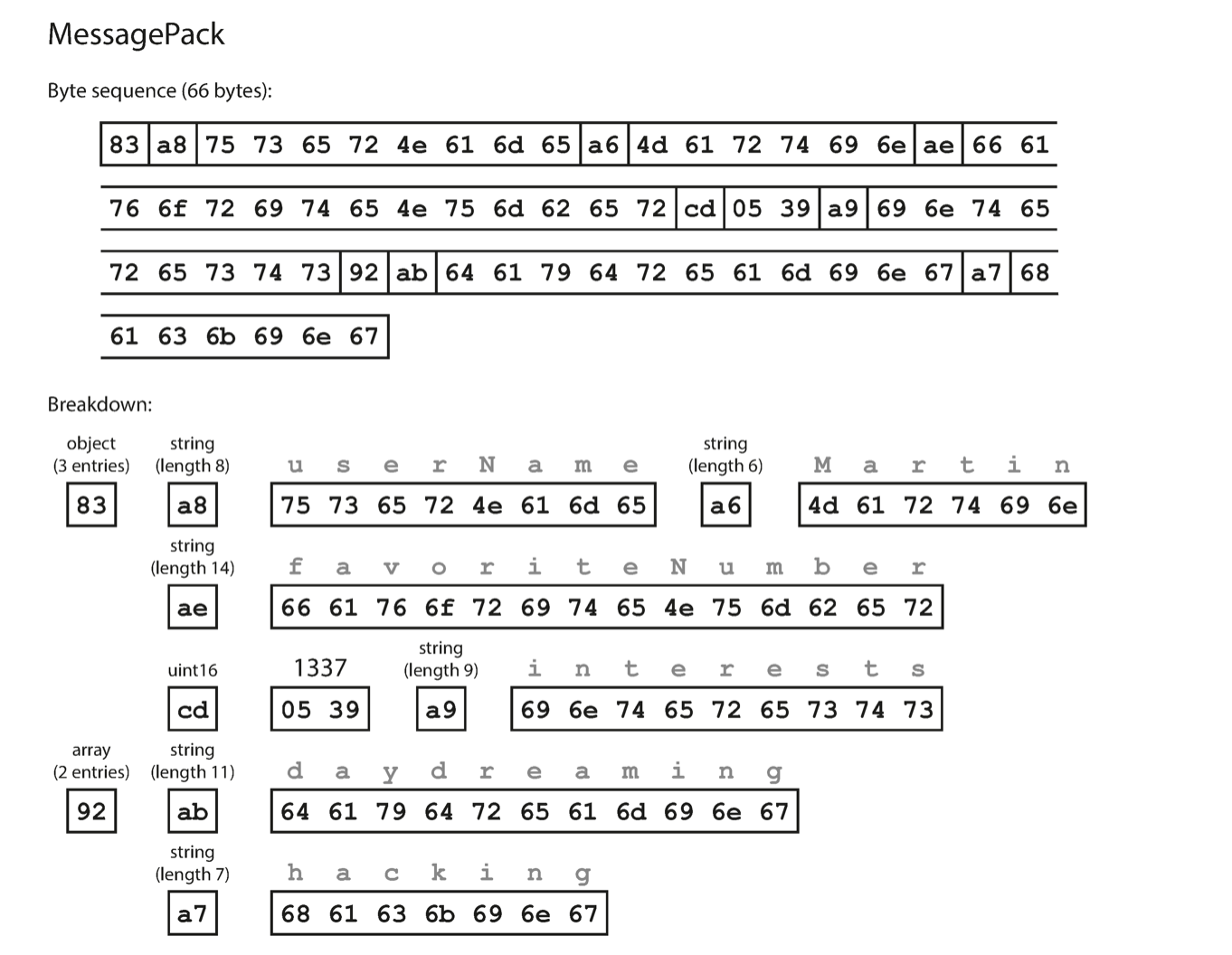
MessagePack encoding example
The MessagePack encoding is 66 bytes, only about 20% smaller than the textual representation. The field names are included for every record, bloating the size.
Thrift example
Thrift IDL:
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}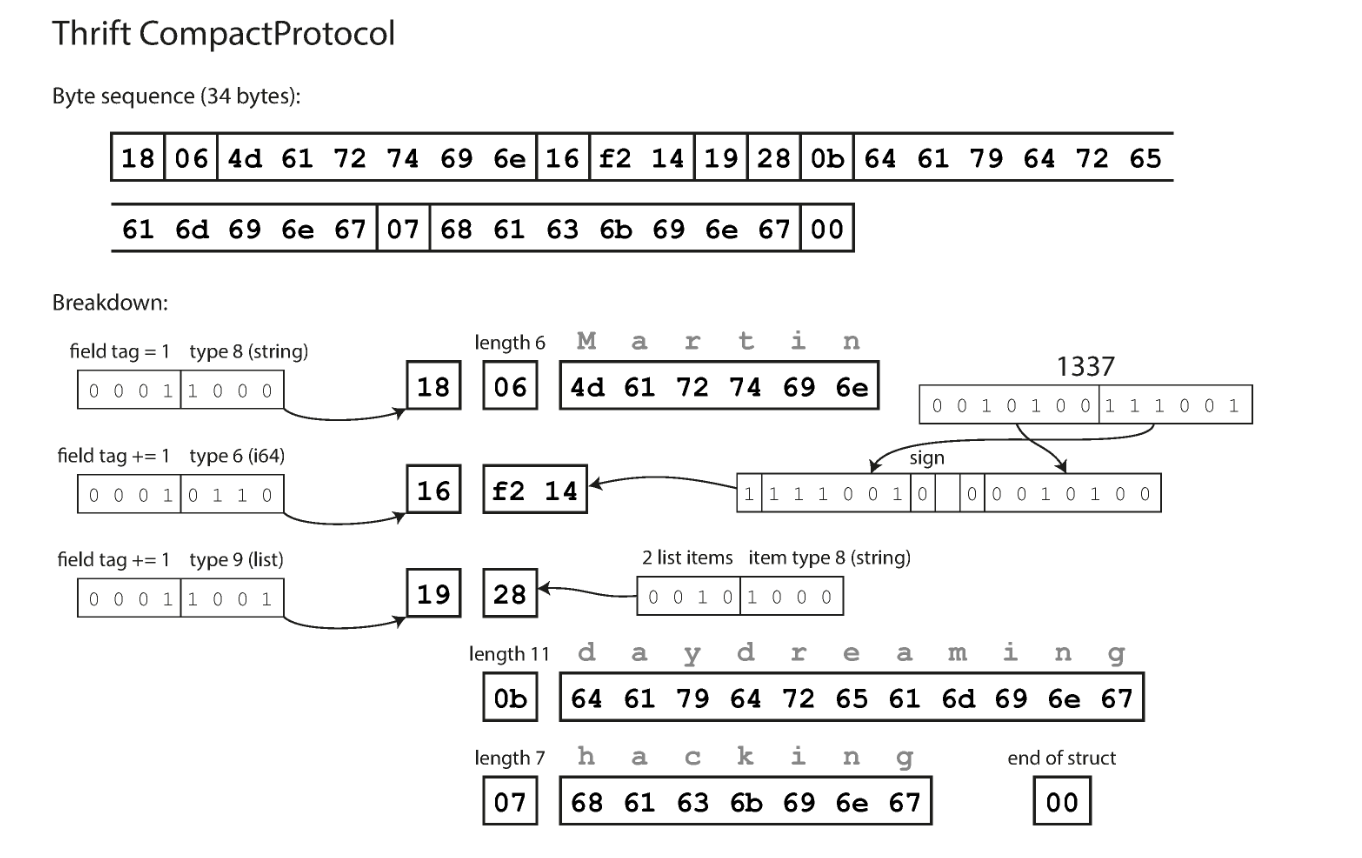
The Thrift Compact Protocol encodes the struct in 34 bytes. It use a variable integer encoding, so 1337 is encoded as 2 bytes rather than 8 bytes. It also stores field tags instead of field names, as well as a code identifying the type of each field. (Protocol Buffers use a similar encoding)
Avro example
Avro IDL:
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}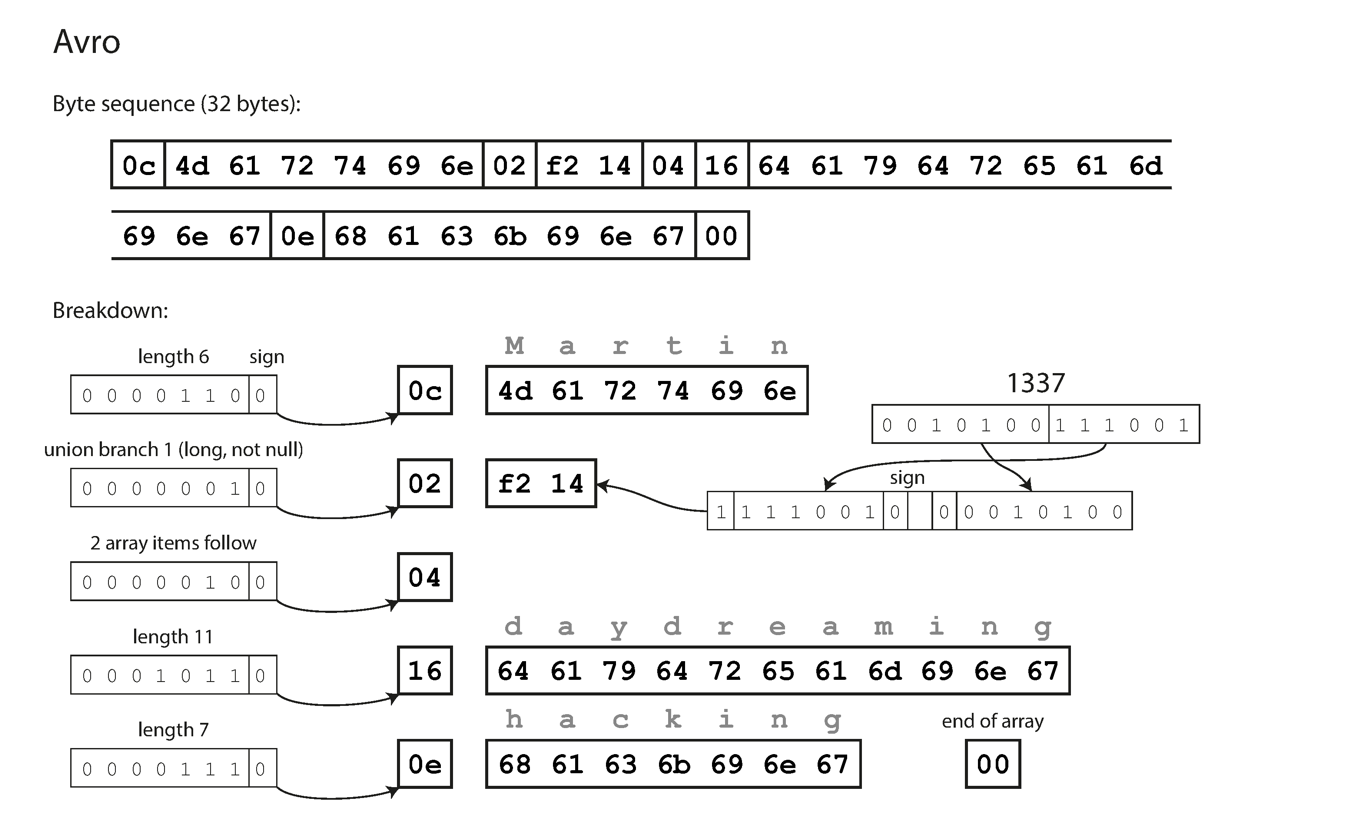
The Avro encoding for this struct is 32 bytes. Like Thrift integers are encoded with a variable-length encoding. Unlike Thrift and Protocol Buffers, there are no field tags identifying each field or type codes identifying the type of the field. Instead the code reading the data relies on the schema to interpret the bytes - so that the schema used to read the data must be the same as that used to write the data.